Design an Automated End-to-End Data Pipeline for a Mobile Pet Grooming Service
- Gina Chee
- May 10, 2024
- 12 min read

Updated: Jun 22, 2025
The objective of this project is to develop a fully automated data pipeline capable of efficiently gathering, processing, and storing data from different sources. Recognizing that real-world data is often distributed across different platforms or channels, the project focuses on two primary approaches: extracting data from the website and accessing files stored locally on our computers.
Process
This project manages two primary data sources: employees data from excel stored in a local computer and customer booking data from the Acuity Scheduling platform. Python is scheduled to gather information from these sources, and apply Extract, Transform, and Load (ETL) process to clean and load these data into the respective staging stables such as Customers, Pets, Address, Appointments, Sales, Services, Job Status, and Roles before being transferred to the final SQL table on Azure database.
Highlights
Due to a small dataset size, the project uses Python and Apple Mac Terminal to automate ETL processes. The ETL staging tables concept is adopted to improve data handling efficiency by enabling error detection and correction in the staging phase before transferring the data to the actual tables. This approach ensures data consistency throughout the entire process.
Data Assessment & Cleaning Tools
Pandas library in Python was essential for exploring and cleaning our dataset, which included customer and employees data. It's extensive capabilities in data wrangling allowed us to align data formats within our Azure SQL database, ensuring consistency during data transfer.
Pandas also excels in reading data from diverse formats and facilitates easy exploration in dataframe format. The library allow us to perform tasks such as removing duplicate rows, converting data types to match our SQL database requirements, and segmenting data into separate dataframes for seamless integrations into SQL.
ETL Pipeline

Data Model - Schema
Snowflake Schema was opted in our data model because it breaks the tables into sub-sections. While this schema introduces complexity, it offers enhanced manageability and flexibility during the analytics phase. This structure facilitates deriving meaningful insights, such as understanding popular customer services and the sales trend.

Note: This project is not intended to cover all aspects of the business but will be focusing on a specific subset.
ETL Tools

Python manages the entire ETL process, leveraging Azure SQL Database for data storage. Python was chosen due to its ease of management during testing with a relatively small dataset. Azure SQL Database was selected for its free-tier option up to a monthly limit and its pay-as-you-go model.
Customer data is extracted from the website using Application Programming Interface (API). A status code of 200 indicates successful data retrieval in JSON format returned to Python.
Concurrently, Python utilizes Pandas to extract and read data from local computer files.
Data Cleaning is performed in Python before loading it into staging tables and subsequently transferring it to our Azure SQL Database’s actual tables.
As an Apple Mac user, I’ve automated the data pipeline using Mac Launchd, a scheduling system native to macOS developed by Apple. This tool allows for automated execution of tasks, ensuring that data processes are managed efficiently and on schedule.
Handling Different Scenarios
Handling Larger Datasets from Multiple Sources: Apache Airflow is a suitable choice. It is designed to manage complex workflows and orchestrate multiple ETL tasks efficiently.
Database Access for Multiple Users: Dedicated database logins can be created. This setup should include stringent security measures to safeguard the integrity of the main database against unauthorized manipulation.
Detailed Report - For more Information
Summary
The objective of this project is to develop a comprehensive automated data pipeline aimed at improving operational efficiency across the business. The SQL database will adopt a snowflake schema format, designed to enhance data organization and accessibility.
The entire ETL process is managed through a Python script, facilitating the integration of customer data from the website and employee data sourced from local files on our computers. This approach ensures seamless extraction, transformation, and loading of data, enabling streamlined operations and informed decision-making.
Environment
This project runs on a Conda environment using Jupyter Notebook. Before using certain library packages, they may need to be installed using pip install commands.
Python Code
#pip install requests
#pip install sqlalchemy
#Import library packages
import pandas as pd
import requests
import re
from datetime import datetime
from sqlalchemy import create_engine, text
import urllib
#Azure Credentials
azure_server = #'Azure_Server_Name'
azure_database = #'Database_Name'
azure_db_username = #'Azure_Username'
azure_db_password = #'Azure_Password'
#Setup connection with Azure Database
driver = '{ODBC Driver 17 for SQL Server}'
odbc_str = f'DRIVER={driver};SERVER={azure_server};PORT=1433;UID={azure_db_username};DATABASE={azure_database};PWD={azure_db_password};Connection Timeout=30'
connect_str = 'mssql+pyodbc:///?odbc_connect=' + urllib.parse.quote_plus(odbc_str)
engine = create_engine(connect_str, echo=True)
#Acuity Scheduling Credentials (Retrieved from the Website)
acuity_user_id = #'API_UserID'
acuity_api_key = #'API_Key'
# Retrieve Customers' Data from Acuity Scheduling
def retrieve_acuity_data():
acuity_appointments_url = f'https://acuityscheduling.com/api/v1/appointments?user={acuity_user_id}'
response_appointments = requests.get(acuity_appointments_url, auth=(acuity_user_id, acuity_api_key))
if response_appointments.status_code == 200:
raw_appointments_data = response_appointments.json()
acuityAppts_df = pd.DataFrame(raw_appointments_data)
return acuityAppts_df
else:
print("Failed to retrieve data:", response_appointments.status_code, response_appointments.text)
return None
#Employees File Path
file_path = #r'FilePath'
sheet_name = 'employees'
#Retrieve employees data from Excel in Local Computer
def retrieve_employees_data(file_path, sheet_name):
employees_df = pd.read_excel(file_path, sheet_name)
employees_df.drop_duplicates(inplace=True)
#Convert startDate and endDate data format
employees_df['startDate'] = pd.to_datetime(employees_df['startDate'], errors='coerce').dt.strftime('%Y-%m-%d')
employees_df['endDate'] = pd.to_datetime(employees_df['endDate'], errors='coerce').dt.strftime('%Y-%m-%d')
#Print data in dataframe format
print("Employees data loaded from Excel:\n", employees_df.head())
return employees_df Scope and Project Steps
Scope
The goal of the project is to create a comprehensive, automated data pipeline that consolidates multiple data sources into a single database system. Centralizing the data enhances the business operational efficiency and provides up-to-date information for analytical purposes enabling meaningful insights to be derived.
Project Steps
Identify the data sources.
Design the SQL Database Schema.
Create the tables on Azure SQL database based on the schema design.
Extract the data from the different sources.
Use API to extract customer data from the website.
Use Pandas package in Python to extract and read employees data from local computer.
Perform Data Cleaning on the data.
Separate the main dataframe into respective dataframes for ease of data transfer into the staging tables.
Run data quality checks against the newly created analytical tables to determine if the data has loaded correctly.
Transfer the data from the staging tables into the final SQL tables.
SQL Database Design
Database Schema Overview
Database Entity Relationship Description
Table 1 & Table 2 | Relationship | Description |
job_status and employees | One-to-Many | Each employee has one job status, and each job status can be assigned to multiple employees. |
employee_role and employees | One-to-Many | Each employee has one role, and each row can be assigned to multiple employees. |
address and employees/ customers/ appointments | One-to-Many | Each address can be associated with multiple employees, customers, and appointments, but each employee, customer, or appointment can only have one address. |
customers and pets | One-to-Many | Each customer can have multiple pets, but each pet belongs to one customer. |
customers and appointments | One-to-Many | Each customer can have multiple appointments, but each appointment is associated with one customer. |
pets and appointments | One-to-Many | Each pet can have multiple appointments, but each appointment is only for one pet. |
services and appointments | One-to-Many | Each service can be associated with multiple appointments, but each appointment includes one service. |
sales and appointments | One-to-One | Each appointment can only have one associated sale, but each sale is linked to one appointment. |
sales and customers/pets | Many-to-One | Each sale is associated with one customer and one pet, but each customer and pet can be associated with multiple sales. |
feedback and customers/pets | Many-to-One | Each feedback entry is associated with each customer and pet, but each customer and pet can have multiple feedback entries. |
Data Sources & Data Gathering
Data Sources
Customers Data (Acuity Scheduling)
Employees Data (Local Computer)
Data Gathering
Exploratory Data Analysis & Data Manipulation
Initial Data Integrity Checklist
Conducting an initial integrity check allow us to understand our data before the cleaning process. This step is important in identifying any inconsistencies and anomalies that needs to be addressed.
Check the Data Volume
Check for Duplicate Records
Check for Null Values
Check for Unique Values in the Columns
Check for Data Types
Exploratory Data Analysis - Employees & Customers Data
Data Exploration aids in understanding the current dataset comprehensively, facilitating informed decision-making during data cleaning and processing.
Employees Data
Accessing the Data
#Employees File Path
file_path = r'filePath'
sheet_name = 'employees'
#Extract, Read File and Import into Dataframe
employees_data = pd.read_excel(file_path,sheet_name)
#Drop any duplicates in Employees Data
employees_data.drop_duplicates(inplace=True)
#Display Result
employees_data
Although there are currently only two employees in the Excel spreadsheet, no duplicates are evident. However, it is prudent to verify for duplicate data to maintain consistency.
Check Employees Data Type
#Check Employees Data Type
employees_data.dtypes
Checking the data type is crucial as it is needed and important to ensure the data type aligns with our SQL database to ensure smooth data flow within our data pipeline into our SQL database. Based on the result, we will need to ensure both ‘startDate’ and ‘endDate’ column are in date format.
Check Data Size
#Check the number of records in the DataFrame
employees_data.shape #Results display in (# of rows, # of columns) format
Reviewing the data shape provides us with an understanding of the dataset’s size and structure. While the current dataset is small, these insights become increasingly crucial as data size scales up. It helps in anticipating computational requirements, optimizing storage, and ensure efficient data processing workflows.
Check for NULL Values
#Check for null values
employees_data.isnull().sum()
It is evident that only the ‘endDate’ column contains 2 null values. This is because both employees are currently active employees.
Understanding Unique Data Values Present in the Datasets
#Check for unique values 'job_status' column
employees_data['job_status'].unique()
#Unique values for 'role' column
employees_data['role'].unique()
#Extract the year the employees join and create a new column called 'startYear'
employees_data['startYear'] = employees_data['startDate'].dt.year
#Unique Values for 'startYear' column
employees_data['startYear'].unique()
Customer Data
We opted to retrieve data from the Acuity Scheduling platform using an API rather than web scraping. This decision mirrors standard practice for data extraction within a organization, ensuring adherence to established business processes. Using the API provides a structured and reliable method to access and integrate data, maintaining data integrity and efficiency in workflows.
Accessing the Data
#Pull data from Acuity Scheduling
#Acuity Scheduling Credentials
acuity_user_id = 'apiUserID'
acuity_api_key = 'apiKey'
#Retrieve Data from Acuity Scheduling via API Connection
acuity_appointments_url = f'https://acuityscheduling.com/api/v1/appointments?user={acuity_user_id}'
response_appointments = requests.get(acuity_appointments_url, auth=(acuity_user_id, acuity_api_key))
#Test Connection
if response_appointments.status_code == 200:
raw_appointments_data = response_appointments.json()
print(json.dumps(raw_appointments_data, indent=4)) #Print results in string (readable format)
else:
print("Failed to retrieve data:", {response_appointments.status_code}, {response_appointments.text})
The Python code can establish a connection with Acuity Scheduling using API credentials, as detailed in the API Documentation. It verifies the connection’s success with a status code of 200, then converts the retrieved data into JSON format and subsequently into a DataFrame for readability. This data is then analyzed to determined the column’s relevance and usage.
Defining the Data Model
Database Schema Model
ETL Pipeline
ETL Process
Extract
#Pull data from Acuity Scheduling
#Acuity Scheduling Credentials
acuity_user_id = 'API_UserID'
acuity_api_key = 'API_Key'
#Retrieve Data from Acuity Scheduling
acuity_appointments_url = f'https://acuityscheduling.com/api/v1/appointments?user={acuity_user_id}'
response_appointments = requests.get(acuity_appointments_url, auth=(acuity_user_id, acuity_api_key))
#Test Connection
if response_appointments.status_code == 200:
raw_appointments_data = response_appointments.json()
print(json.dumps(raw_appointments_data, indent=4)) #Print results in string (readable format)
else:
print("Failed to retrieve data:", {response_appointments.status_code}, {response_appointments.text})Customer data is extracted from Acuity Scheduling using its API, utilizing a specific API User ID and API Key associated with the account. Upon successful retrieval of data, confirmed by a status code of 200, the information is returned in JSON format to facilitate human-readable interpretation.
Employees Data Retrieval from Local Computer
#Employees File Path
file_path = r'filePath'
sheet_name = 'employees'
#Extract and Read File
employees_data = pd.read_excel(file_path, sheet_name=sheet_name)
#Print dataframe
employees_dataEmployees data is extracted from a local file stored on our computer, using the Pandas library for efficient data handling and manipulation. This enable us to integrate the employees data into a centralized data source.
Transform
Employees Data
Format Date Columns - startDate and endDate
#Convert employees date format
employees_data['startDate'] = pd.to_datetime(employees_data['startDate'], errors='coerce').dt.strftime('%Y-%m-%d')
employees_data['endDate'] = pd.to_datetime(employees_data['endDate'], errors='coerce').dt.strftime('%Y-%m-%d')
#Display Result
employees_data
The startDate and endDate are formatted to align the data types in our SQL database to ensure consistency and compatibility with the database structure.
Standardize to Lower Case format in DataFrame
#Standardize format in dataframe - lowercase
for col in employees_data.select_dtypes(include=['object']).columns:
employees_data[col] = employees_data[col].str.lower().str.strip()
#Display result
employees_dataThe DataFrame is transformed to lowercase format for consistency across all data entries. This standardization helps to maintain uniformity and simplifies data process and analysis tasks.
Customers Data
Split 'formsText' Column
#Extract 'formsText' column and input into formsTextCol variable
formsTextCol = acuityAppts_df['formsText']
#Store formsText in a list
extracted_formsText_list = []
#Iterate in each row in formsText column
for text in formsTextCol:
address_match = re.search(r"Address:\s*(.*)", text)
name_match = re.search(r"Pet's Name\s*:\s*(.*)", text)
breed_match = re.search(r"Pet's Breed\s*:\s*(.*)", text)
age_match = re.search(r"Pet's Age\s*:\s*(.*)", text)
remarks_match = re.search(r"Remarks:\s*(.*)", text)
#Store extracted values from formsText column
extracted_details = {
'address': address_match.group(1) if address_match else None,
'petName': name_match.group(1) if name_match else None,
'petBreed': breed_match.group(1) if breed_match else None,
'petAge': age_match.group(1) if age_match else None,
'remarks': remarks_match.group(1) if remarks_match else None
}
extracted_formsText_list.append(extracted_details) # Append to a list
#Print extracted details DF
extracted_details_df = pd.DataFrame(extracted_formsText_list)
extracted_details_df
#Combine extracted df to the main df
acuityAppts_df = pd.concat([acuityAppts_df, extracted_details_df], axis=1)
acuityAppts_df
Within the Acuity Scheduling platform, a form is created to collect specific information such as pet details, grooming address, and additional notes relevant for groomers during customer bookings. Regular expressions are used to extract string that match predefined patterns into corresponding tables, including address, petName, petBreed, petAge, and remarks.
Split 'type' Column
#Split 'type' column
type_column_split = acuityAppts_df["type"].str.split(" - ", expand=True)
acuityAppts_df["serviceType"] = type_column_split[0]
acuityAppts_df["groomType"] = type_column_split[1]
#Clean the groomType column
acuityAppts_df["groomType"] = acuityAppts_df["groomType"].apply(lambda value: re.sub(r'\s*\(.*?\)', '', value) if value else value)
acuityAppts_df["groomType"] = acuityAppts_df["groomType"].apply(lambda value: re.sub(r'\s*\+.*', '', value) if value else value)
acuityAppts_df["groomType"] = acuityAppts_df["groomType"].apply(lambda value: value.strip().title() if value else value)
#Display Result
acuityAppts_df
The ‘type’ column is separated into two distinct columns: ‘serviceType’ and ‘groomType’. This process involves applying regular expressions to classify data into categories such as ‘full grooming’, ‘basic grooming’, or ‘one-off service’, while specifying the particular type of grooming service offered.
Columns to be Dropped
#Columns to be dropped
drop_columns = [
'id','datetimeCreated','datetime',
'priceSold','amountPaid','appointmentTypeID','addonIDs',
'classID','calendar','calendarID','certificate','confirmationPage',
'confirmationPagePaymentLink','location','notes','timezone',
'calendarTimezone','canClientCancel','canClientReschedule',
'labels','forms','type','formsText'
]
#Drop columns
acuityAppts_df.drop(columns=[col for col in drop_columns if col in acuityAppts_df.columns],inplace=True)
acuityAppts_dfThe columns in the code snippet above are removed because they are not necessary for our SQL database.
Columns to be Renamed
#Columns to be renamed
rename_columns = {
'date':'apptDate',
'dateCreated':'salesDate',
'time':'startTime',
'price':'salesAmount',
'paid':'amountPaid',
'type':'groomType',
'category':'petType',
'canceled':'canceledAppt'
}
#Display the result after renaming the columns
acuityAppts_df.rename(columns=rename_columns,inplace=True)
acuityAppts_dfThe columns in the code snippet above are renamed to match the titles used in our SQL database, making it easier for users to identify and understand them.
Format Time Columns - startTime and endTime
#Check for presence of 'startTime' and 'endTime' columns before conversion
if 'startTime' in acuityAppts_df.columns:
acuityAppts_df['startTime'] = acuityAppts_df['startTime'].apply(
lambda time_str: datetime.strptime(time_str, '%I:%M%p').strftime('%H:%M:%S') if time_str and ':' in time_str and 'AM' in time_str or 'PM' in time_str else time_str
)
else:
print("'startTime' column not found")
if 'endTime' in acuityAppts_df.columns:
acuityAppts_df['endTime'] = acuityAppts_df['endTime'].apply(
lambda time_str: datetime.strptime(time_str, '%I:%M%p').strftime('%H:%M:%S') if time_str and ':' in time_str and 'AM' in time_str or 'PM' in time_str else time_str
)
else:
print("'endTime' column not found")
# Display Result
acuityAppts_df
The time columns - ‘startTime’ and ‘endTime’ are formatted to align the data types in our SQL database. This ensures consistency and compatibility with the database structure.
Format Date Columns - salesDate and apptDate
#Check for presence of 'salesDate' and 'apptDate' columns before conversion
if 'salesDate' in acuityAppts_df.columns:
acuityAppts_df['salesDate'] = pd.to_datetime(acuityAppts_df['salesDate'], errors='coerce').dt.strftime('%Y-%m-%d')
else:
print("'salesDate' column not found")
if 'apptDate' in acuityAppts_df.columns:
acuityAppts_df['apptDate'] = pd.to_datetime(acuityAppts_df['apptDate'], errors='coerce').dt.strftime('%Y-%m-%d')
else:
print("'apptDate' column not found")
#Display result
acuityAppts_dfThe date columns - ‘salesDate’ and ‘apptDate’ are formatted to align the data types in our SQL database to ensure consistency and compatibility with the database structure.
Format Boolean Columns - canceledAppt and amountPaid
#Convert 'canceledAppt' boolean conversion
if 'canceledAppt' in acuityAppts_df.columns:
acuityAppts_df['canceledAppt'] = acuityAppts_df['canceledAppt'].apply(lambda x: 'yes' if x else 'no')
#Convert 'amountPaid' boolean conversion
if 'amountPaid' in acuityAppts_df.columns:
acuityAppts_df['amountPaid'] = acuityAppts_df['amountPaid'].apply(lambda x: 'yes' if x else 'no')
#Display result
acuityAppts_dfThe columns - ‘canceledAppt’ and ‘amountPaid’ are adjusted to maintain data type consistency, allowing only ‘yes’ or ‘no’ values. This aligns with the requirements of our SQL database.
Standardize to Lower Case Format in DataFrame
#Standardize format in dataframe - lowercase
for col in acuityAppts_df.select_dtypes(include=['object']).columns:
acuityAppts_df[col] = acuityAppts_df[col].str.lower().str.strip()
#Display result
acuityAppts_dfThe DataFrame is transformed to lowercase format for consistency across all data entries. This standardization helps to maintain uniformity and simplifies data process and analysis tasks.
Split Employees and Customers DataFrame into Respective Tables to Match SQL DB
#Split dataframe into respective tables to match SQL DB
address_df = acuityAppts_df[['address']].drop_duplicates()
services_df = acuityAppts_df[['serviceType','groomType']].drop_duplicates()
customers_df = acuityAppts_df[['firstName','lastName','email','phone','address']].drop_duplicates()
pets_df = acuityAppts_df[['petName','petType','petAge','petBreed','remarks','address']].drop_duplicates()
appointments_df = acuityAppts_df[['apptDate','startTime','endTime','duration','canceledAppt','address']].drop_duplicates()
sales_df = acuityAppts_df[['salesDate','salesAmount','amountPaid','apptDate','address']].drop_duplicates()
employees_df = employees_data[['name','job_status','role','startDate','endDate','email','phone','address']].drop_duplicates()The data is partitioned into separate tables - address, services, customers, pets, appointments, sales, and employees - to correspond with the tables in our SQL database. This partitioning ensures smooth integration when importing the data into our SQL database.
Load
Azure Credentials
#Azure Credentials
azure_server = 'azureServer'
azure_database = 'databaseName'
azure_db_username = 'databaseUserName'
azure_db_password = 'databasePassword'Set-up Connection with Azure Database
#Create Connection with Azure Database
driver = '{ODBC Driver 17 for SQL Server}'
odbc_str = f'DRIVER={driver};SERVER={azure_server};PORT=1433;UID={azure_db_username};DATABASE={azure_database};PWD={azure_db_password};Connection Timeout=30'
connect_str = 'mssql+pyodbc:///?odbc_connect=' + urllib.parse.quote_plus(odbc_str)
engine = create_engine(connect_str, echo=True)Transfer Data into Staging Tables
#Set up database connection and check if table name exist before importing data into staging table
with engine.begin() as connection:
df.to_sql(table_name, connection, if_exists='replace', index=False)
print(f"Data transferred to staging table {table_name} successfully.")
#Transfer data to staging
transfer_data_to_staging(engine, address_df, 'staging_address')
transfer_data_to_staging(engine, services_df, 'staging_services')
transfer_data_to_staging(engine, customers_df, 'staging_customers')
transfer_data_to_staging(engine, pets_df, 'staging_pets')
transfer_data_to_staging(engine, appointments_df, 'staging_appointments')
transfer_data_to_staging(engine, sales_df, 'staging_sales')
transfer_data_to_staging(engine, employees_staging_df, 'staging_employees')
transfer_data_to_staging(engine, job_status_df, 'staging_job_status')
transfer_data_to_staging(engine, employee_role_df, 'staging_employee_role') Automate ETL Data Pipeline
As a Macbook user, I utilize Launchd to automate our ETL data pipeline, configured through Apple Terminal. Managing automation tasks with Launchd on macOS necessitates a property list (plist).
The entire process is illustrated below:





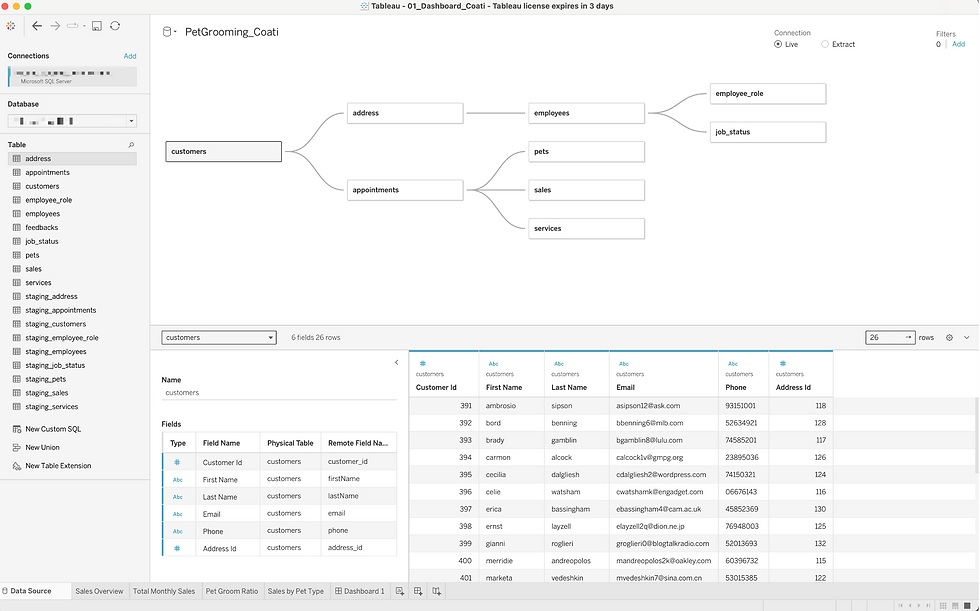
Sales Dashboard
To complete the final step of the data pipeline, sales dashboard is created using Tableau. This is to finalize and demonstrate how the automated data pipeline supports effective data visualization and analysis.
The data was available upon signing into Microsoft SQL Server on Tableau, ensuring seamless integration. Since tables are already connected in our SQL database, we can easily perform inner joins on these tables to conduct our visualizations.
The entire process is illustrated below:


Complete Python Script
Python Code


